














































































松灵PiPER机械臂在HybridVLA框架中的创新实践
前言:在具身智能领域,视觉 - 语言 - 动作(VLA)模型是机器人技术发展关键。但现有 VLA 模型在动作生成策略上问题突出: 自回归方法量化动作离散化,破坏动作连续性,影响高精度操作; 扩散方法依赖预训练视觉 - 语言模型特征提取,动态推理能力不足。且多智能体协作时,难以突破单任务局限实现动态协同; 本文以松灵PiPER机械臂和Franka Research 3机械臂为实验载体,通过HybridVLA框架,实现智能体间动态协同,从而有效克服现有VLA模型在动作生成策略及多智能体协作方面存在的困难。
我们作为松灵机器人的代理商为用户提供高效的解决方案如有产品购买需求请联系:ming@bft-robot.com
技术框架与核心参数
机器人实验载体
松灵PiPER机械臂:6轴自由度设计 松灵夹爪 英特尔 D435
Franka Research 3机械臂:7自由度设计 前端Franka夹爪
技术框架
HybridVLA框架:融合扩散与自回归策略协同训练方案 协同动作集成机制
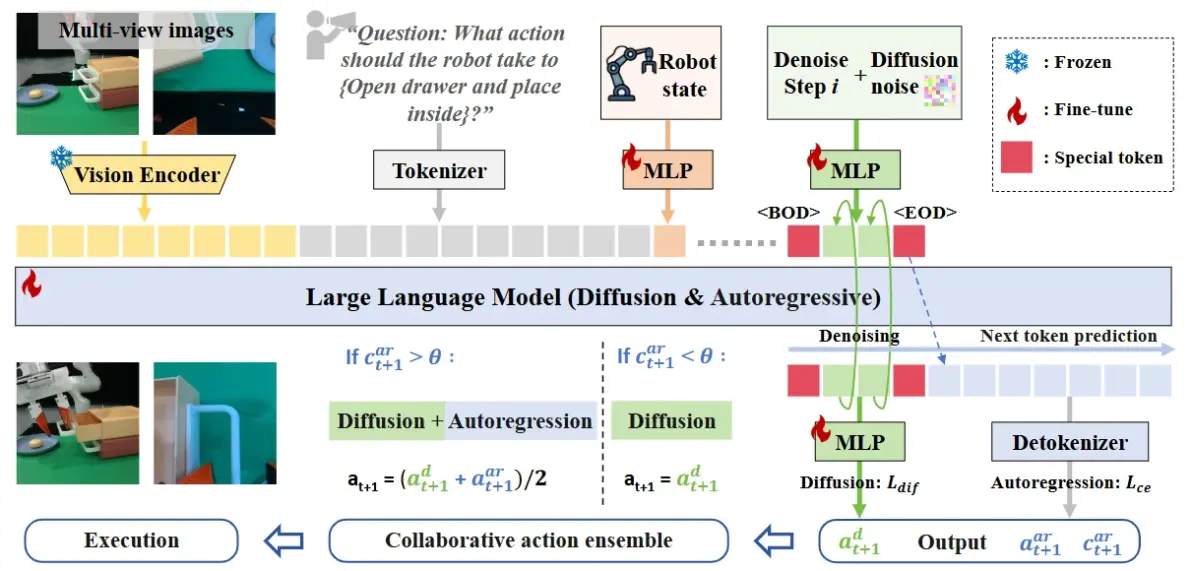
图2:HybridVLA框架。无论采用何种形式,输入数据都会被编码并连接到我们格式化的令牌序列中。为了将扩散集成到LLM中,HybridVLA同时将去噪时间步长和噪声动作投影到令牌序列中。标记标记<BOD>(扩散开始)和<EOD>(扩散结束)旨在弥合这两种生成方法。通过采用协作训练来明确地整合来自两种生成方法的知识,这两种动作类型相互强化,并自适应地组合在一起以控制机器人手臂。对于HybridVLA的输出,通过迭代去噪生成连续动作,而自回归生成离散动作,所有这些都在下一个令牌预测过程中进行
策略开发全流程数据准备与预处理
数据采集:收集 RLBench 模拟数据(10 类任务)、Franka 单臂 / AgileX 双臂真实数据(各 5 类任务),整合 35 个开源数据集(76 万条轨迹)用于预训练。
数据处理:动作编码为 7-DOF(单臂)/14-DOF(双臂),添加扩散噪声;多模态数据(视觉、语言、机器人状态)标记化,用特殊标记分隔扩散与自回归部分。
模型架构设计
核心组件
视觉编码器:DINOv2/SigLIP(7B 模型)或 CLIP(2.7B 模型)提取多视图特征。
LLM:LLAMA-2(7B)或 Phi-2(2.7B)处理多模态标记,输出扩散(连续动作)和自回归(离散动作)标记。
动作生成模块:扩散头通过 DDIM 采样去噪,自回归头解码离散标记并计算置信度。
关键机制
协作动作集成:根据自回归标记置信度(阈值 0.96)动态融合两种动作。
KV 缓存加速:提升扩散推理速度至 9.4 Hz。
实验验证
训练策略
预训练:在跨域数据集上训练 5 个 epoch,学习通用动作语义关联。
微调:模拟(RLBench)和真实场景(单 / 双臂任务)中优化混合损失(Ldif+Lce)
模拟实验(RLBench 基准)
模拟测试:10 类任务平均成功率 74%,优于基线方法(如 CogACT 60%)。
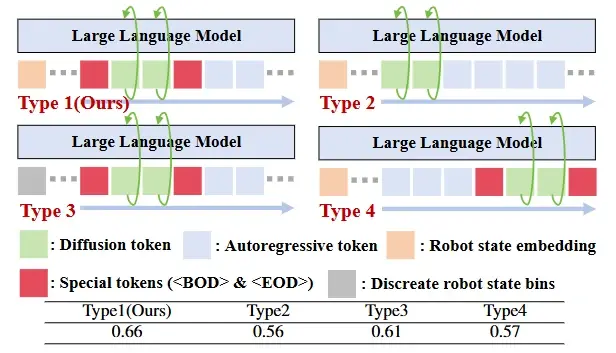
表1。探索和验证我们提出的令牌序列公式。该模型使用扩散和自回归生成进行训练,但仅在10个模拟任务中对基于扩散的动作(HybridVLA-dif)进行了测试。
定量结果(成功率 S.R. & 推理速度)

表2。在RLBench上比较我们提出的方法和基线。我们在多任务设置中训练所有方法[87],并报告每个任务的成功率(S.R.)。成功条件遵循RLBench中的定义。“HybridVLA-dif”指的是仅依赖于扩散过程的行为预测。(7B)、(2.7B)和(2.6B)是指VLA模型中使用的LLM的大小。
在RLBench 基准的模拟实验中,HybridVLA(7B)在 10 类任务中平均成功率达 74%,显著优于 OpenVLA(41%)、CogACT(60%)等基线方法,尤其在 Close laptop(95%)、Toilet seat down(100%)等任务中表现突出。 仅使用扩散推理的 HybridVLA-dif(7B)平均成功率 66%,推理速度 9.4 Hz,兼顾效率与精度。2.7B 模型虽平均成功率 58%,但推理速度达 12.3 Hz。整体而言,HybridVLA 在成功率和推理速度上实现了较好平衡,优于多数对比方法。
核心结论:HybridVLA 通过 LLM 内扩散与自回归的协作,在成功率和推理速度间取得平衡,尤其在语义 - 动作联合建模任务中优势显著。
现实实验
实验过程:单臂实验(Franka Research 3)
任务:5 类真实操作(Pick and place、Unplug charger、Pour water、Wipe blackboard、Open drawer and place inside),每任务 100 条示教轨迹,多视图输入(front + wrist camera)
对比方法:π₀ (2.6B)、CogACT (7B)(仅单臂支持)
双臂实验(AgileX PiPER)
任务:5 类协作任务(Pick and place、Lift ball and place、Place bottles at rack、Wipe blackboard、Fold shorts),每任务 100 条轨迹,三视图输入(external + left/right wrist cameras)
对比方法:π₀ (2.6B)(双臂基线)


表4。我们的方法和基线在现实世界场景中的比较。我们在单一任务设置中训练所有方法[110],并报告成功率。成功取决于基于任务是否完成的人工评估。由于CogAct缺乏对多视图图像的支持,而多视图图像对于双臂任务至关重要[8,20],因此我们仅使用π0进行双臂比较。
关键发现:Franka 单臂任务成功率 80%-95%,AgileX 双臂任务 66%-80%
泛化能力验证变量设置:
未见物体:用充电器替代训练中的红色方块(Pick and place 任务)
复杂背景:在操作区域添加杂物(如花盆)
光照变化:模拟夜间环境(低光照 + 色偏)
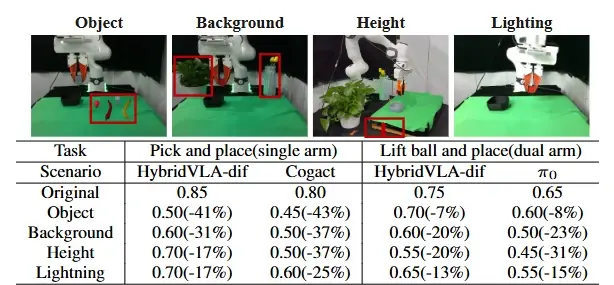
表5。一般化。“对象”、“背景”、“高度”和“照明”分别表示看不见的操纵对象、背景、空间位置和照明条件。上图显示了四个看不见的测试场景,红色框突出了关键差异。
关键发现:HybridVLA-dif 在 “未见物体” 场景中成功率下降 7%-41%,显著低于 π₀的 8%-43%,证明其对语义泛化的更强适应性。
核心结论:多视图输入与协作动作集成机制使模型在单/ 双臂任务中表现稳健,泛化能力优于传统扩散方法,为工业和服务机器人提供了可落地的通用框架。
论文详情:https://hybrid-vla.github.io/
关于BFT白芙堂机器人
BFT(白芙堂)机器人是智能机器人一站式服务平台,能为客户提供机器人选型、培训、解决方案、在线采购、本地化定制等高性价比的一站式服务。平台产品涵盖协作机器人、工业机器人、移动机器人、SCARA机器人、服务机器人、机器人夹爪、三维机器视觉设备、3D工业相机等十余种品类,实现机器人产业链产品全覆盖,并广泛应用于工业制造、实验室自动化、智慧零售、教育科研等行业。平台已与国内外知名机器人企业达成战略合作,并拥有专业的工程师团队,能为客户提供算法及系统定制、职校教学、科研实验室平台搭建、机器人展厅定制等服务,支持一对一技术支持和二次开发。










